На весенней конференции Heisenbug в онлайне я поделился своими мыслями о том, где что выгоднее использовать для интеграционного тестирования
Программирую
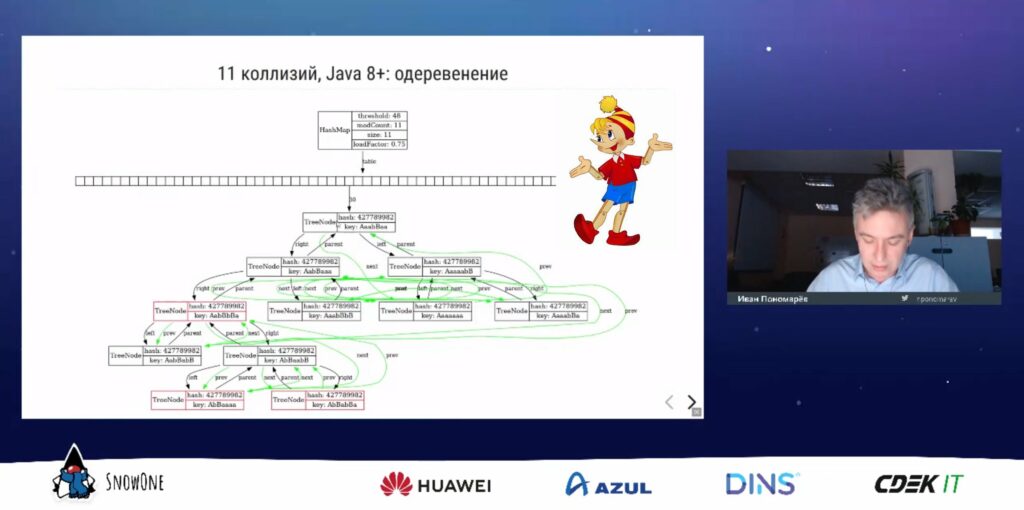
Хабрапост по Lightweight Java Visualizer
Опубликовал хабрапост с пересказом прошлогоднего доклада про LJV: https://habr.com/ru/post/599045/
Mind the Data Gap Podcast, ep. 3
Heisenbug show: 10 лет Selenide
Видеозаписи Heisenbug 2021 Moscow
Интервью с ребятами из компании PVS-Studio о security:
Обсуждение того, как устроена конференция Heisenbug:
Круглый стол: Как контролировать качество кода
В рамках онлайн-конференции Podlodka Backend Crew принял участие в круглом столе «Как контролировать качество кода» с Тагиром Валеевым и Маргаритой Недзельской
Круглый стол по JUnit и asserts
Поучаствовал в Heisenbug Show на тему лучших практик использования JUnit и ассертов с Анатолием Коровиным, Владимиром Ситниковым и Андреем Солнцевым
Доклад LJV: Чему нас может научить визуализация структур данных в Java
Новый подкаст (2)_после правок.final.doc
Сходил с Николаем Поташниковым в «Новый подкаст 2» обсудить, почему AsciiDoctor — вершина долгой эволюции решений для документирования, и где он хорош кроме лишь документирования.
Kafka streams testing: A deep dive
На онлайн-конференции Joker 2020 совместно с John Roesler сделали доклад про особенности тестирования Kafka Streams приложений.